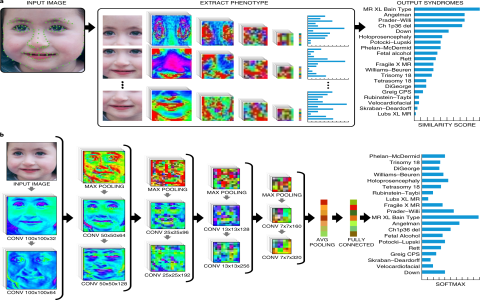
Okay, so today I wanted to mess around with something I’ve been calling “entropy loss syndrome.” It’s not a real technical term, just something I came up with to describe a problem I’ve seen when training neural networks.
The Setup
I started by whipping up a simple dataset. Nothing fancy, just some random numbers that I could easily manipulate. Think of it like a practice canvas before you start on a real painting.
Then, I built a basic neural network model. Again, nothing too complex. Just a few layers to keep things manageable. I was using a popular deep learning library to put it together, but it really doesn’t matter which one you use, the principles are the same.
The Problem
The whole point of this experiment was to see what happens when the “entropy loss,” which is a measure of randomness, gets too low during training. What I mean is the network that learns so well that the loss value goes down and down.
I did this by tweaking the training parameters. I basically forced the model to get too good too quickly.
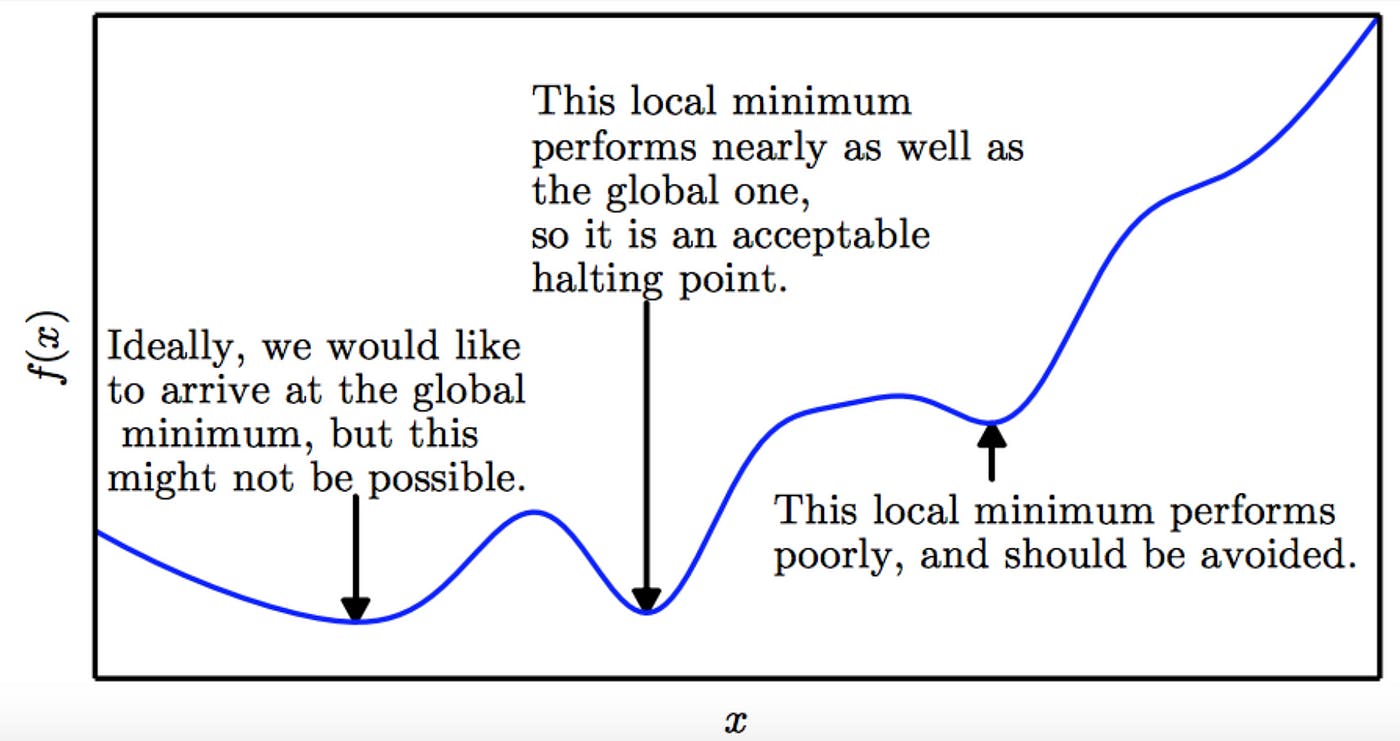
The Experiment
I kicked off the training process and watched the numbers scroll by. At first, everything looked normal. The loss was decreasing, the accuracy was increasing – all good signs. But then, things started to get weird.
- The loss dropped super low, almost to zero. You’d think that’s a good thing, but in this case, it was a red flag.
- The model started making overly confident predictions. It was like it was too sure of itself.
- When I tested it on new data, it actually performed worse than before! It was like it had memorized the training data instead of actually learning the underlying patterns.
The Result
What I think it means. It means the model gets stuck in a rut and can’t adapt to anything new. It’s like a student who only memorizes the answers to practice questions but can’t actually solve a similar problem on the real exam.
Key takeaways, you really need to make sure you are carefully monitoring your training. Don’t just chase the lowest possible loss. Look at how the model performs on a separate validation set, and consider using techniques like regularization to prevent it from getting “too smart” for its own good.
So, that’s my little experiment with “entropy loss syndrome.” It’s a reminder that sometimes, a bit of healthy randomness is a good thing when you’re teaching a machine to learn.





{kind=link}