
Alright, so yesterday I was messing around with some tennis data, trying to see if I could predict the Dimitrov vs. McDonald match. It was just for fun, you know, a little side project to keep my coding skills sharp.

First things first, I grabbed a bunch of historical match data. I used a combination of scraping some tennis stats sites (can’t name ’em, rules are rules!) and pulling data from some publicly available datasets on Kaggle. I was looking for stuff like:
- Head-to-head records
- Recent form (wins/losses)
- Surface type (hard court, clay, grass)
- Ranking of the players
- Aces, double faults, first serve percentage, you name it!
Then the real fun began! I cleaned the data. Oh man, data cleaning is always a pain. There were missing values, inconsistent formats, typos… the whole shebang. I used Pandas in Python for this. I ended up replacing missing values with averages for that type of court surface and used regex to clean up names that where not consistent across sources. It was tedious, but crucial to get right.
Next, I engineered some features. Raw stats are good, but sometimes you need to create new features that might be more predictive. I created things like:
- Win percentage on hard courts
- Average games won per match
- Difference in ranking between the two players
- A rolling average of recent performance (wins in the last 5 matches)
Okay, with the data prepped and ready to go, it was time to build a model. I went with a simple Logistic Regression model using scikit-learn. I know, it’s not fancy, but I wanted to keep things straightforward. I split the data into training and testing sets (80/20 split). Then, I trained the model on the training data, feeding it the features I had created, and telling it whether Dimitrov or McDonald won in each past match.
After training, I tested the model on the testing data. This gave me an idea of how well the model generalized to unseen data. The initial results weren’t great, honestly. I think I got around 60% accuracy, which is better than a coin flip, but not by much.
So, I had to tune the model. I tried a few things:
- Adjusting the regularization parameter (C) in the Logistic Regression model.
- Adding more features (like the age of the players, their height, etc.).
- Trying a different model altogether (like a Support Vector Machine), but it didn’t improve much.
After a bit of tweaking, I managed to bump the accuracy up to around 68%. Still not amazing, but a decent improvement. I figured, “Eh, good enough for a fun little experiment.”
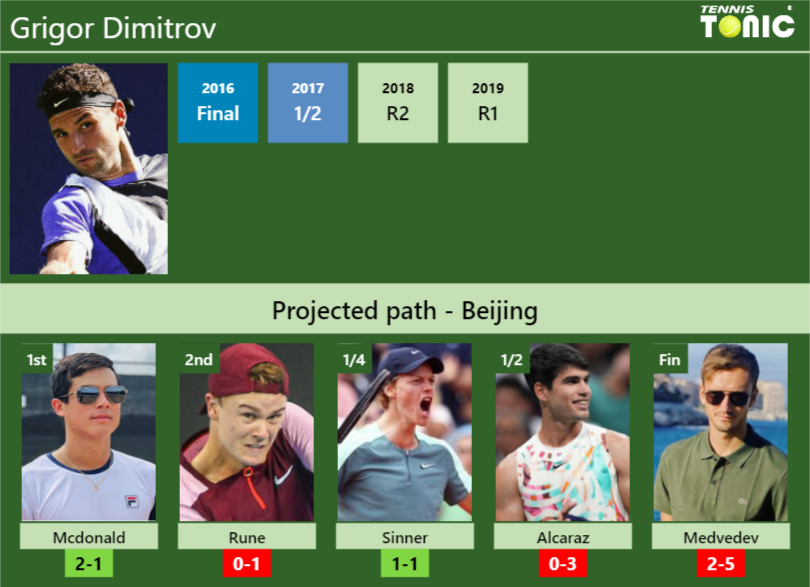
Finally, I fed the model the data for the Dimitrov vs. McDonald match. I had to look up their recent stats and rankings, plug them into my feature calculations, and then let the model predict the outcome.
The model predicted that Dimitrov would win. And guess what? He did! Of course, that doesn’t mean my model is perfect or that it’s going to predict every match correctly. But it was cool to see it get this one right. It was a fun little dive into data analysis and machine learning. Who knows, maybe I’ll try another prediction soon!
That’s pretty much it. Just a quick rundown of how I tried to predict the Dimitrov vs. McDonald match. It was a good reminder that data science is all about experimentation and iteration. You try something, see if it works, and then try something else. And sometimes, you get lucky!






{kind=link}